yaico Agentic Pipelines — yaico Plattform
Ganze Data Pipelines per Claude. Vom Prompt bis in den Cluster.
Eine neue Pipeline anlegen — Quellen rein, Transformationen dazu, Dashboard raus — war ein Mehrtages-Projekt. Mit yaico Agentic Pipelines reicht ein Prompt an einen KI-Agenten wie Claude: Er generiert den Code, führt ihn aus, korrigiert im Loop, deployt ihn als CronJob in Kubernetes und betreibt ihn anschließend — Monitoring, Debug und Erweiterung inklusive. Alles auf Basis unserer DAG-Engine Reveal.
→ 20 Minuten reden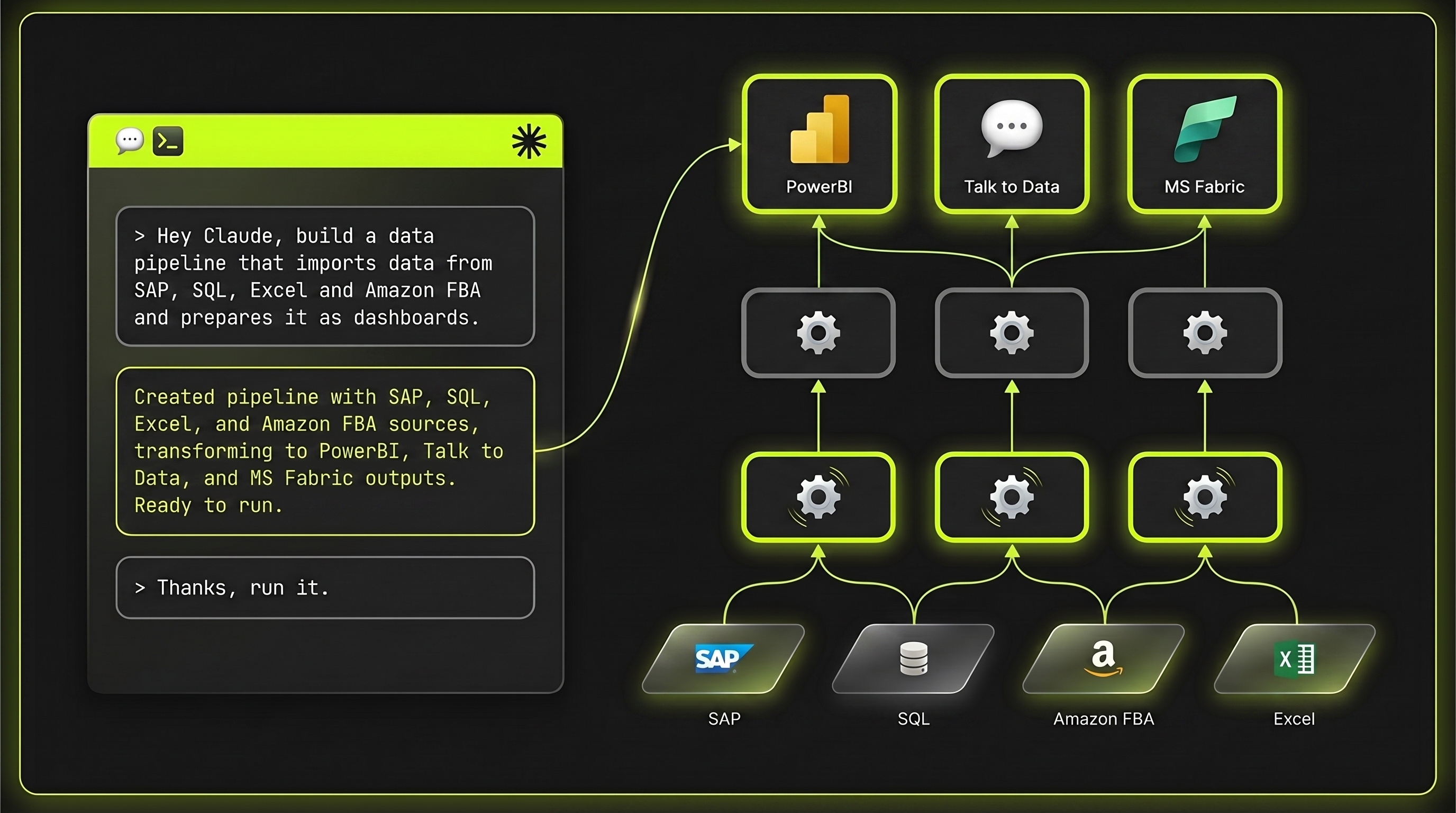
Nicht das LLM ist neu. Die Pipeline-Infrastruktur ist agentenfähig gebaut.
yaico Agentic Pipelines läuft auf unserer DAG-Engine Reveal. Jeder Verarbeitungsschritt ist eine selbstbeschreibende Klasse in einer flachen Vererbungslinie, der DAG steht als Mermaid-Graph direkt im Code, jeder Run schreibt einen Audit-Trail, und das Deployment liegt deklarativ als Helm-Chart im selben Git. Genau darin kann ein Agent navigieren — lesen, schreiben, ausführen, korrigieren. Das Prinzip lässt sich auf andere Pipeline-Frameworks übertragen, solange Code, Container und Cluster sauber zusammenhängen.
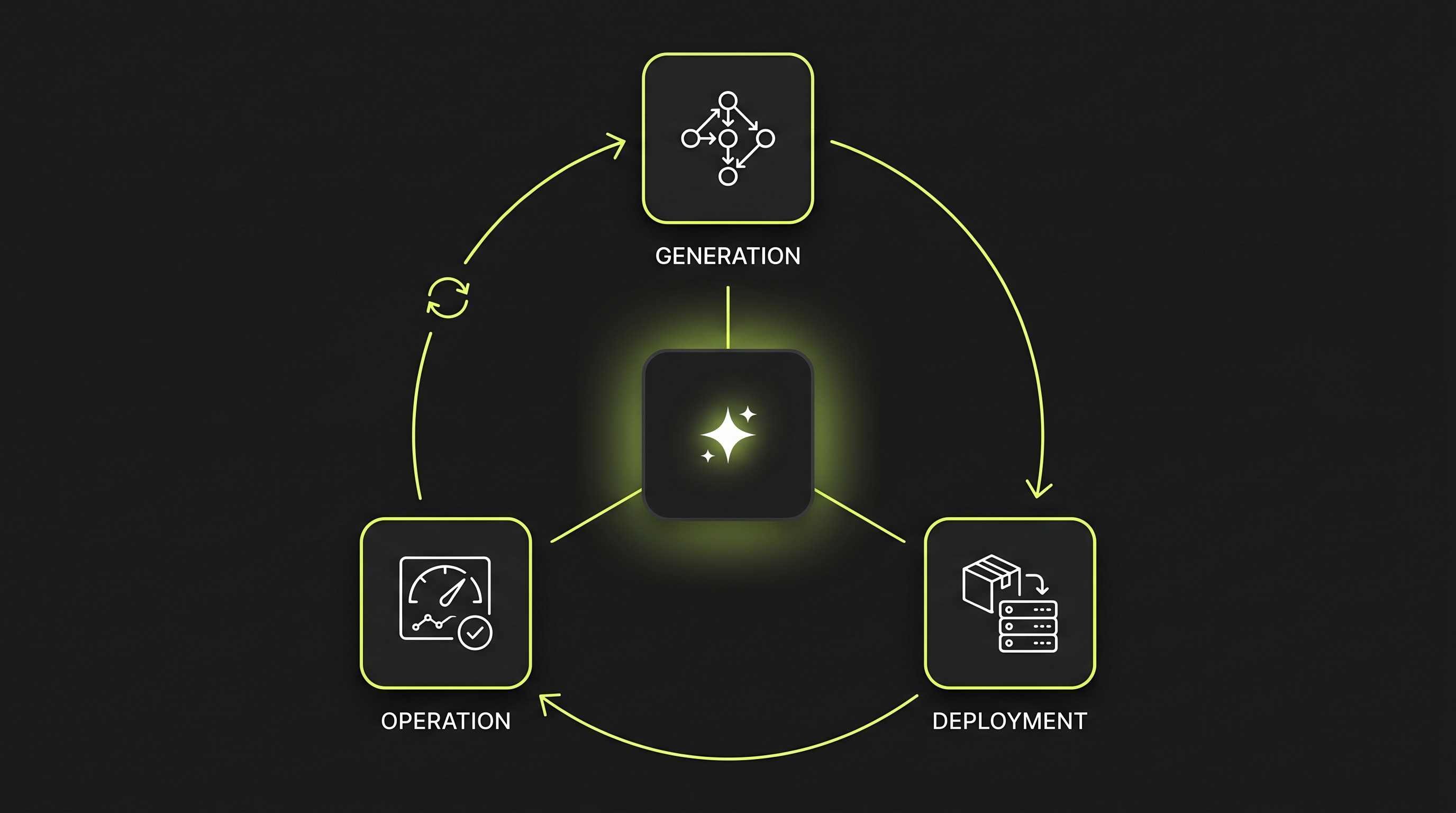
Der vollständige Lebenszyklus
Drei Phasen — alle agentengetrieben.
Von der ersten Idee bis zum laufenden Betrieb führt derselbe Agent durch die Pipeline.
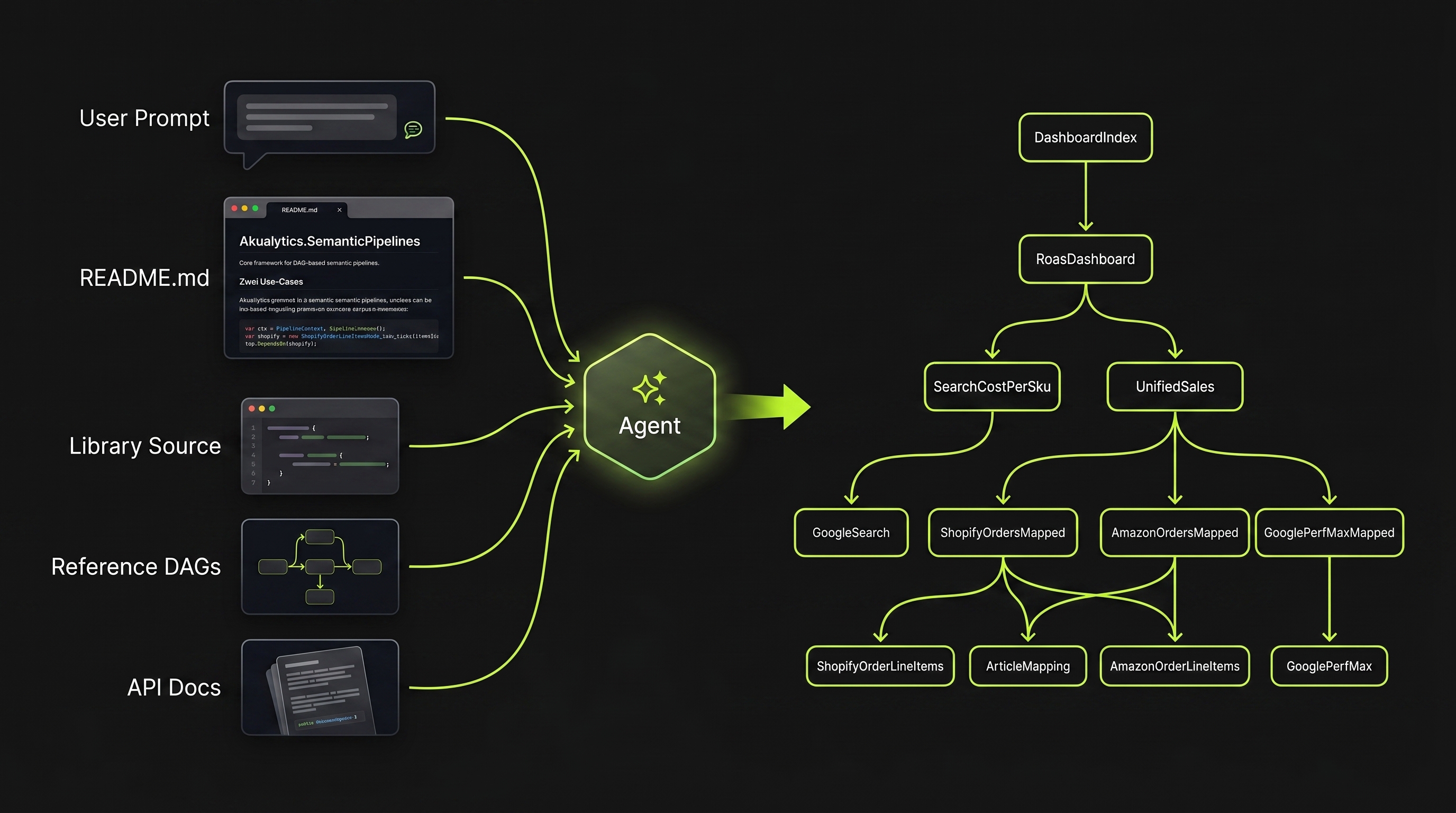
Pipeline aus dem Prompt
Claude liest Repo, Samples und API-Docs, leitet fehlende Nodes per Analogie ab, verdrahtet den DAG, führt ihn lokal aus, prüft den Audit-Trail und korrigiert im Loop — bis ein grüner, getesteter DAG steht. PR statt Entwurf.
→ Wie Generation funktioniert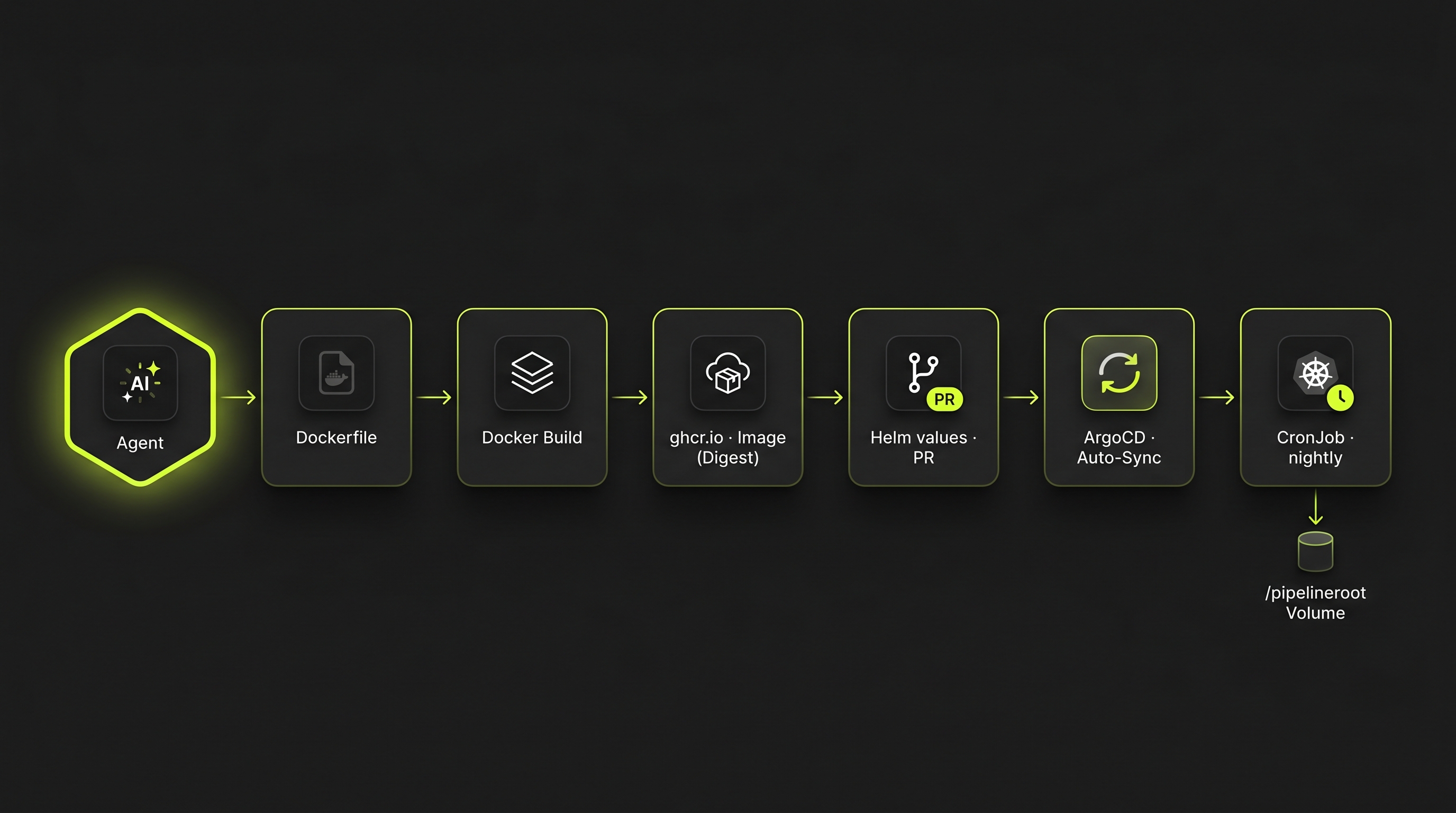
Vom Programm in den Cluster
Multi-stage Dockerfile, Image per Digest gepinnt, Helm-Chart aktualisiert — der Rollout läuft per Pull Request über ArgoCD-GitOps. Kein kubectl apply von Hand, Rollback ist ein git revert.
Betrieb ohne Log-Diving
Monitoring, Debug, Extend, Run — alles per Prompt. Der Agent liest den Audit-Trail, findet die Fehlerursache im Code, spielt den Fix ein und triggert ad-hoc Runs. Operations ohne Operations-Person.
→ Wie Operation funktioniertIn Action
Zwei Sätze an Claude — eine lauffähige Pipeline.
> Hey Claude, baue ein Sales-Dashboard, das Shopify- und Amazon-Bestellungen zusammenführt. → Ich lese die README und gehe den Library-Source durch — Reference-DAGs, API-Docs, die Node-Klassen. ShopifyOrderLineItemsNode und AmazonOrderLineItemsNode existieren bereits. → Lege SalesDashboardPipeline.cs an — zwei Source-Nodes, ein DashboardIndex, Abhängigkeiten verdrahtet, Run-Aufruf am Ende. → Dry-Run prüft die DAG-Struktur, echter Lauf verarbeitet die Records, Audit-Trail grün. Tests geschrieben. PR #142 erstellt — bitte reviewen.
Der Agent generiert nicht nur Code — er dreht die Schleife aus Ausführen → Status lesen → Korrigieren selbst, statt sie an einen Menschen zurückzugeben.
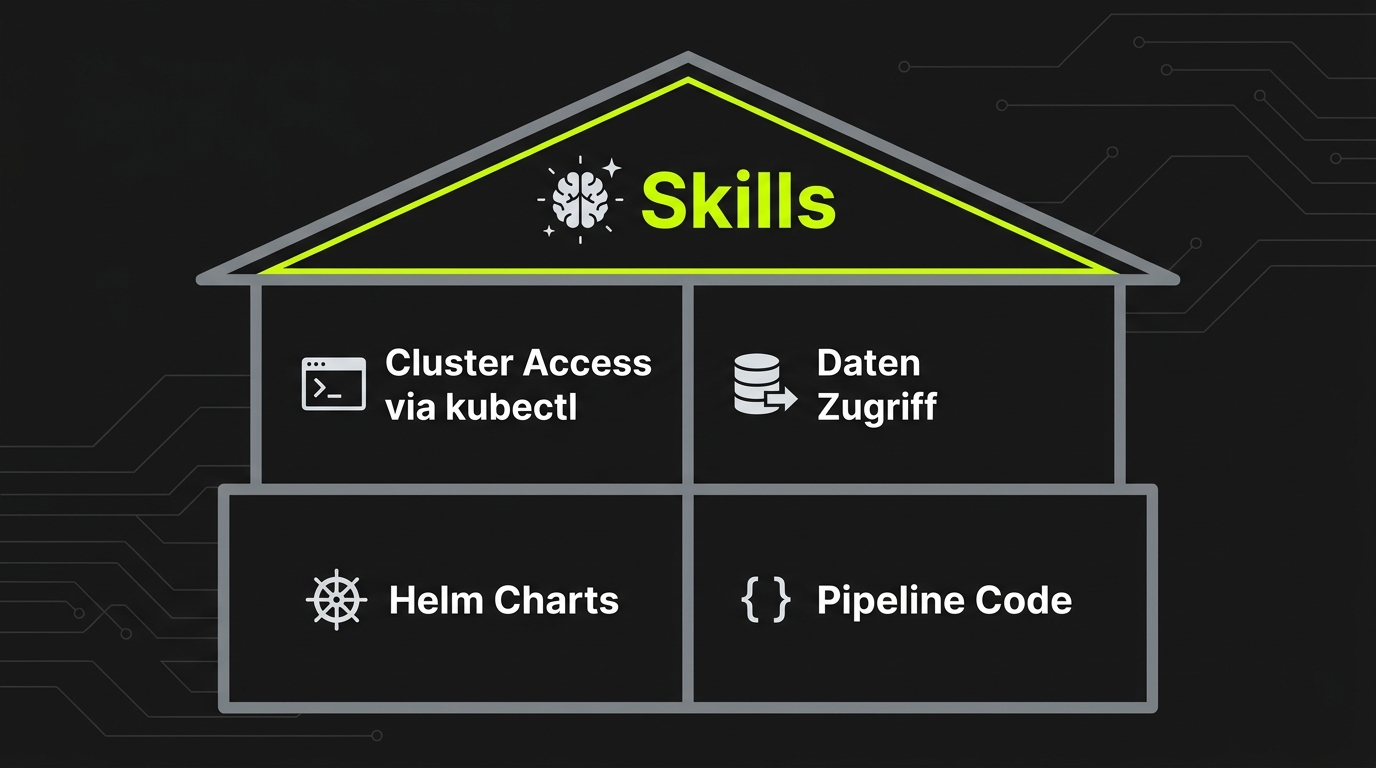
Was der Agent braucht
Vier Fundamente — plus der Bootstrapper.
Stehen diese Querverbindungen, wird aus „kann lesen" ein „weiß, wo es losgeht".
Pipeline-Implementierung
Zugang zum echten Repo — kein Wiki-Auszug. Der Agent liest Quellcode, versteht DAG-Strukturen und Transformationslogik direkt.
Daten-Orte
Wo liegen Eingangsdaten, wo landen Ausgaben? Connection Strings, Buckets, Schemas — alles, um Daten direkt zu inspizieren.
Helm Chart
Image-Tags, Environment-Variablen, Kubernetes-Ressourcen. Der Agent liest das deklarative Deployment-Setup und kennt den Betrieb.
Querverbindungen
Code, Helm-Chart, Cluster und Daten-Orte hängen zusammen. Vom Fehler in Node A direkt zum Chart und zum laufenden Pod — ohne menschlichen Zwischenschritt.
Die technische Grundlage
Warum das heute funktioniert.
Selbstbeschreibende Node-Klassen. Jede Node trägt Input-Typ, Output-Typ und Transformationslogik in sich. Der Agent liest die ganze Pipeline aus dem Code — ohne externe Doku.
Mermaid-DAG im Code. Die Abhängigkeitsstruktur ist maschinenlesbar im Repository — kein manuell gepflegtes Diagramm, das veraltet.
Audit-Trail pro Run. Jeder Lauf wird protokolliert, jede Node grün/gelb/rot. Der Agent vergleicht Runs und erkennt Regressionen.
Kubernetes-nativ. Reveal läuft auf Kubernetes. Der Agent greift über kubectl direkt ein — Jobs triggern, Logs lesen, Image-Tags aktualisieren.

Für wen
Wo sich das Setup-Investment auszahlt.
Data Engineers & Berater
Wer Pipeline auf Pipeline baut: Das Setup zahlt sich ab der zweiten Pipeline aus. Generation wird ein halber Tag, Debug Minuten statt Stunden.
Software-Vendor-Teams
Reporting- und Analytics-Features ins eigene Produkt einbauen — Kunden erweitern und debuggen ihre Pipelines selbst, mit einem KI-Agenten als Interface.
BI-Teams
Bestehendes BI nicht ablösen, sondern erweitern: neue Datenquellen und neue Views per Prompt — kein IT-Ticket.
Pipelines bauen lassen — oder betreiben lassen.
Wir zeigen euch in 20 Minuten, wie yaico Agentic Pipelines auf eurem Stack aussehen würde. Und wenn ihr Build und Betrieb nicht selbst stemmen wollt: Unser Agent Ops Team übernimmt den agentengetriebenen Betrieb eurer Pipelines als Managed Service.
→ 20 Minuten reden