Eine neue Data Pipeline anlegen — Shopify-Bestellungen rein, Amazon-Bestellungen rein, kombiniertes Sales-Dashboard raus — war bis vor kurzem ein Mehrtages-Projekt. Connector schreiben, Spalten mappen, Tests dazu, Deployment vorbereiten. Mit dem richtigen Setup im Repo — wie es yaico Reveal out of the box mitbringt — reicht heute ein Prompt an Claude:
In Action: eine neue Data Pipeline als DAG per Claude
> Hey Claude, baue ein Sales-Dashboard, das Shopify- und Amazon-Bestellungen
zusammenführt.
→ Ich lese die README von Akualytics.SemanticPipelines und gehe den
Library-Source durch — Reference-DAGs, API-Docs, die Node-Klassen.
ShopifyOrderLineItemsNode und AmazonOrderLineItemsNode existieren bereits.
→ Lege SalesDashboardPipeline.cs an — zwei Source-Nodes, ein DashboardIndex,
Abhängigkeiten verdrahtet, Run-Aufruf am Ende:
Das Ergebnis ist lauffähiger Source-Code, der sofort durch Claude getestet und optimiert wird, bis er das gewünschte Ergebnis produziert:
var ctx = PipelineContext.Create("/pipelineroot").EnsureDirectories();
var shopify = new ShopifyOrderLineItemsNode(ShopifyConnectorConfig.FromEnv(), context: ctx);
var amazon = new AmazonOrderLineItemsNode (AmazonSpApiConnectorConfig.FromEnv(), context: ctx);
var top = new DashboardIndexNode("Sales", ctx);
top.DependsOn(shopify);
top.DependsOn(amazon);
Helpers.RunSemDag(top, false, Console.WriteLine);
2 Stunden statt 2 Tage — und das Ergebnis ist nicht ein Entwurf, sondern eine produktionsfähige Pipeline. Claude generiert nicht nur den Code, sondern führt ihn lokal aus, prüft die Audit-Logs, korrigiert Spalten-Mappings und Edge-Cases im Loop, schreibt die Tests dazu und reicht erst einen PR ein, wenn der DAG sauber durchläuft. Was bei dir landet, geht in den nächsten Cron-Run.
Zwei Sätze an Claude, eine lauffähige Pipeline, Tests und Audit-Trail gleich mit dabei. Das geht nicht, weil das LLM heute besser ist — es geht, weil unsere DAG-Engine Reveal so gebaut ist, dass der Agent darin navigieren kann. Und genau darum geht’s in diesem Artikel.
Dies ist Teil 1 einer dreiteiligen Serie:
- Generation (dieser Artikel) — neue Pipelines aus dem Prompt heraus
- Deployment — Docker-Build, Helm-Chart, ArgoCD-Rollout per PR
- Operation — Monitoring, Debug, Extend, Run, alles agentengetrieben
Was der Agent zum Generieren liest
Damit das Beispiel oben funktioniert, braucht der Agent vier Artefakte direkt im Source-Repo:
README.md im Source-Repo — Der schnellste Einstieg. Was die Pipeline tut, welche Konventionen gelten, wo Beispiele liegen. Eine knappe README ist mehr wert als 50 Seiten Confluence.
Samples — Existierende Connectoren, Transformations-Nodes, Tests. Der Agent lernt euer Pattern by example. Wer Samples pflegt, generiert per Prompt — wer keine hat, schreibt jedes Mal von Hand.
API-Docs im Code — DocStrings, XML-Comments, Interface-Definitionen. Source-of-truth ist der Code, nicht eine externe Doku-Site. Der Agent referenziert sie direkt beim Schreiben.
Source-Code — Der Agent liest die gesamte Codebase. Klare Klassennamen, kurze Methoden, wenig Magic. Was für Code-Review gut ist, ist auch für LLM-Lesbarkeit gut.
Diese vier Säulen sind der statische Kontext — sie liegen einfach im Repo. Was sie aktiviert, ist der User-Prompt: er ist der Bootstrap, der die Beziehung herstellt. Der Prompt sagt, welche der vorhandenen Bausteine zu welcher neuen Pipeline verknüpft werden sollen. Aus „führe Shopify- und Amazon-Bestellungen zu einem Sales-Dashboard zusammen” wird so die konkrete Verdrahtung: Die Säulen liefern das Material, der Prompt den Bauplan — und der Agent zieht beides zum fertigen DAG zusammen.
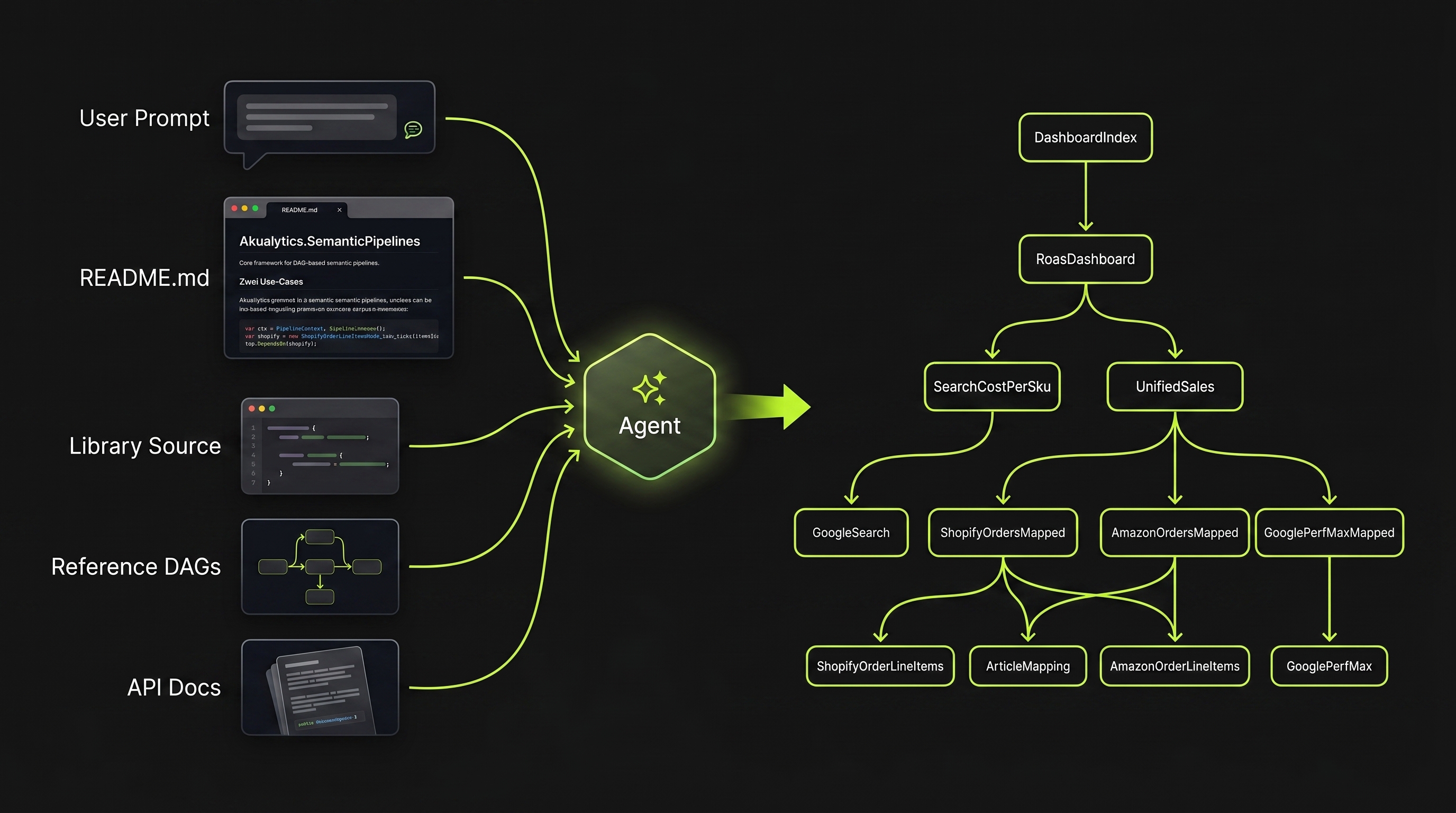
Sind diese vier Säulen da, wird Generation eine Frage von Stunden statt Tagen. Fehlt eine, schreibt der Agent jedes Mal von Hand mit — oder rät, mit entsprechendem Risiko. Reveal liefert genau diese vier Säulen out of the box.
Anatomie einer Reveal-Node
Damit ein Agent eine Pipeline generieren kann, muss er wissen, woraus eine Pipeline besteht. In Reveal ist das angenehm wenig: jeder Verarbeitungsschritt ist eine Klasse in einer kurzen, flachen Vererbungslinie. Keine YAML-Operatoren, keine Plugin-Registry, keine versteckten Side-Effects — die Vererbungshierarchie ist die Dokumentation.
Ganz oben steht das Interface IDagNode (es erbt von einem generischen Baum-Interface, ILinqToTree). Es legt fest, was jede Node im Graphen können muss: ihren PipelineContext kennen, einen Namen liefern (GetName()) und Abhängigkeiten anmelden (DependsOn(child)). Darüber definiert ISemPipeNodeBase den Lebenszyklus einer Daten-Node — CustomToSemantic(), ToDeltaBucket(), ToDashboard(), ToHtmlReport() und die FlatCube-Schritte.
Implementiert wird das in zwei Stufen: DagNode kümmert sich um den reinen Graphen (Children, DependsOn, Status-Tracking), und die abstrakte SemPipeNodeBase<T> setzt darauf den kompletten Daten-Lebenszyklus — Delta-Bucket, Audit-Tracking, Folder-Anlage. Der Typparameter T ist der Record-Typ, den die Node produziert, und muss von SemanticRecord erben. Für den Normalfall gibt es die nicht-generische SemPipeNodeBase : SemPipeNodeBase<SemanticRecord>.
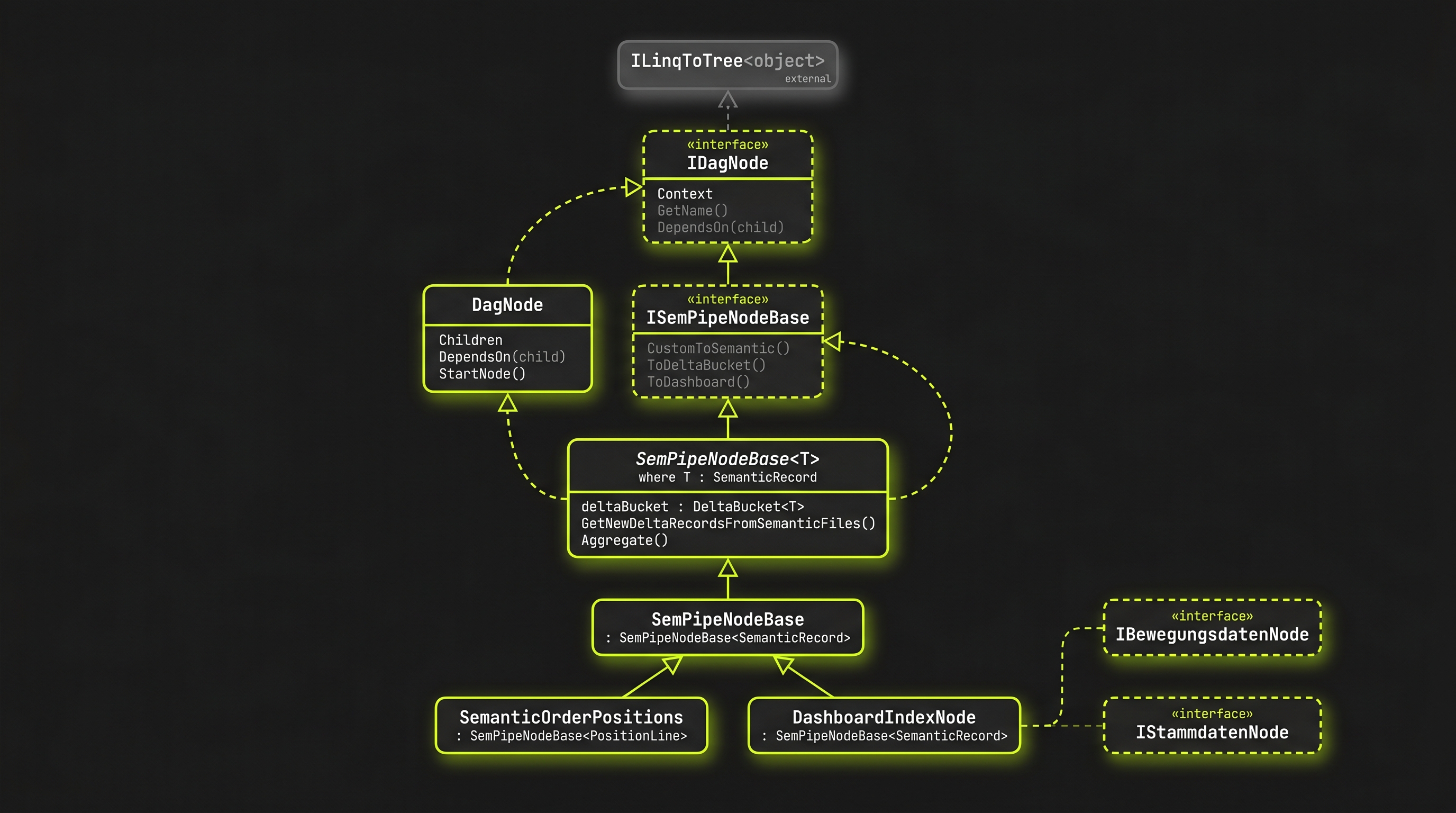
Eine konkrete Node erbt von SemPipeNodeBase<T> und überschreibt nur die Punkte, an denen sie sich von der Norm unterscheidet. Eine Source-Node, die Bestellpositionen einliest, beantwortet im Wesentlichen zwei Fragen — „wie parse ich meine Rohzeilen?” und „wie aggregiere ich sie?” —, alles andere erbt sie:
public class SemanticOrderPositions
: SemPipeNodeBase<SemanticOrderPositions.PositionLine>, IBewegungsdatenNode
{
public SemanticOrderPositions(PipelineContext context = null)
: base(SemPipeNodeBase.UploadType.Automatic, ";",
nodeName: "SemanticOrderPositions", context: context) { }
// Rohzeilen aus dem Semantic-Folder → typisierte Records für den DeltaBucket
protected override IEnumerable<PositionLine> GetNewDeltaRecordsFromSemanticFiles(
IEnumerable<object[]> semanticLines) =>
semanticLines.InferDataTypes().DoParse().Select(t => new PositionLine
{
OrderId = t[nameof(PositionLine.OrderId).D()].Value.ToString(),
ArticleNumber = t[nameof(PositionLine.ArticleNumber).D()].Value.ToString(),
PositionPrice = Convert.ToDecimal(t[nameof(PositionLine.PositionPrice).D()].Value),
Date = (DateTime)t[nameof(PositionLine.Date).D()].Value,
});
// Gleiche Position mehrfach geliefert? Summieren.
protected override IEnumerable<PositionLine> Aggregate(IEnumerable<PositionLine> input) =>
input.GroupBy(l => l)
.Select(g => { g.Key.PositionPrice = g.Sum(l => l.PositionPrice); return g.Key; });
// Das Schema der Node — gleich nebenan, kein externes Mapping.
public class PositionLine : SemanticRecord
{
public string OrderId { get; set; }
public string ArticleNumber { get; set; }
public decimal PositionPrice { get; set; }
public DateTime Date { get; set; }
public override object Id => $"{OrderId}{ArticleNumber}{Date:yyyy-MM-dd}";
}
}
Drei Dinge, die ein Agent hier sofort erkennt:
- Der Record-Typ steht direkt daneben.
PositionLine : SemanticRecordist eine geschachtelte Klasse — das Schema der Node ist im selben File ablesbar. - Marker-Interfaces statt Config.
IBewegungsdatenNode(Transaktionsdaten) bzw.IStammdatenNode(Dimensionen, Hierarchien) klassifizieren die Node. Reveal rendert daraus automatisch die richtige Form im DAG-Diagramm — Bewegungsdaten als Parallelogramm, Stammdaten als Zylinder. - Nur die Abweichung wird geschrieben. API-Fetch, Folder-Handling, Delta-Propagation und Dashboard-Export erbt die Node von
SemPipeNodeBase<T>. Überschrieben werden hier nur Parsing und Aggregation.
Genau diese Konsequenz macht den Unterschied für den Agenten: Wenn jede Node demselben Schema folgt, kann Claude eine neue Node per Analogie schreiben. Er liest SemanticOrderPositions, versteht das Muster und leitet die nächste Source-Node daraus ab — ohne ein Framework-Handbuch.
Der Generierungs-Loop
Mit dieser Struktur im Rücken läuft die eigentliche Generierung in einem klaren Loop ab. Der Prompt aus dem Beispiel oben — „baue ein Sales-Dashboard aus Shopify und Amazon” — durchläuft fünf Schritte:
1. Repo lesen & Pattern erkennen. Claude scannt die vier Säulen (README, Samples, API-Docs, Source). Er findet die Vererbungslinie um SemPipeNodeBase<T> und prüft, welche Bausteine schon existieren und welche fehlen.
2. Fehlende Nodes ableiten. Wo ein Baustein fehlt, leitet Claude ihn aus dem nächstgelegenen Sample ab — eine neue Klasse von SemPipeNodeBase<T>, der Record-Typ von SemanticRecord, dazu das passende Marker-Interface. Überschrieben werden nur die Abweichungen, meist GetNewDeltaRecordsFromSemanticFiles (Parsing) und ggf. Aggregate. Typsicherheit ist hier der Freund des Agenten: Passt der Record-Typ nicht, meldet der C#-Compiler es sofort — der Agent sieht den Fehler, bevor ein einziges Record fließt.
3. DAG verdrahten. Claude instanziiert die Nodes, hängt sie mit DependsOn aneinander und setzt die DashboardIndexNode an die Spitze:
var ctx = PipelineContext.Create("/pipelineroot").EnsureDirectories();
var orders = new SemanticOrderPositions(ctx);
var top = new DashboardIndexNode("Sales", ctx);
top.DependsOn(orders);
top.RunSemDag(reinitialize: false, discordlogger: Console.WriteLine);
4. Struktur prüfen — ohne 30-Minuten-Lauf. Bevor Claude die echte Pipeline startet, ruft er RunSemDagDryRun auf: Das rendert nur die DAG-Struktur (Mermaid + DAG-HTML), ohne API-Calls und Transformationen. Claude prüft die Verdrahtung, bevor eine teure Pipeline-Runtime überhaupt anläuft.
5. Ausführen, Audit prüfen, korrigieren, PR. Dann der echte Lauf. RunSemDag arbeitet jede Node in topologischer Reihenfolge ab und durchläuft pro Node denselben Lebenszyklus — GetCustomApiData → CustomToSemantic → ToDeltaBucket → ValidateNode → ToDashboard → ToHtmlReport. Nach jedem Schritt schreibt der Runner den aktuellen Status als Mermaid-Graph (pipelinestatus.mmd, jede Node grün/gelb/rot). Claude liest diesen Graphen und die Konsole wie ein Entwickler, erkennt sofort, wenn eine Node 0 Records liefert oder rot wird, korrigiert im Loop und führt erneut aus — bis der DAG sauber durchläuft. Erst dann schreibt er die Tests dazu und reicht einen PR ein. Was beim Menschen landet, ist ein grüner, ausgeführter, getesteter DAG — kein Entwurf.
Dieser Loop ist der eigentliche Grund für das „2 Stunden statt 2 Tage”: nicht, weil der Agent schneller tippt, sondern weil er die Schleife aus Ausführen → Status lesen → Korrigieren selbst dreht, statt sie an einen Menschen zurückzugeben.
Das Ergebnis ist ein fertiges Programm, das als Docker-Image gebaut und in einen Kubernetes-Cluster deployt werden kann. Auch diese Schritte — Image-Build, Helm-Chart-Update, Rollout — übernimmt Claude. Mehr dazu in Teil 2: Pipeline Deployment.
Im zweiten Teil zeige ich, wie der fertige DAG in Produktion kommt — Docker-Build, Helm-Chart, ArgoCD-Rollout per Pull Request. Im dritten Teil dann das Operating der laufenden Pipeline: Monitoring, Debug, Extend, Run.
Weiter zu Pipeline Deployment →
Reveal kennenlernen →