Dies ist Teil 3 der Serie KI-Agenten als Pipeline-Engineers. Im ersten Teil ging es um Pipeline Generation — wie ein Agent aus einem Prompt heraus neue Pipelines, Connectoren und Transforms baut —, im zweiten Teil um Deployment: Docker-Build, Helm-Chart und ArgoCD-Rollout per PR. Dieser Artikel zeigt die dritte Phase: Operation — Monitoring, Debug, Extend, Run, alles agentengetrieben.
Die Grundlage dafür ist weiterhin unsere DAG-Engine Reveal — und das Prinzip dahinter lässt sich auf andere Pipeline-Frameworks anwenden, solange die richtigen Voraussetzungen stimmen.
Pipeline Operation
Was der Agent grundsätzlich braucht
Bevor ein KI-Agent sinnvoll mit einer Data Pipeline arbeiten kann, braucht er Zugang zu allen relevanten Informationen. Das klingt offensichtlich — aber in der Praxis fehlt dieser Kontext fast immer.
Vier Säulen, die stehen müssen:
Pipeline-Implementierung — Zugang zum Repo. Der Agent muss den echten Code lesen können, kein Wiki-Auszug. LLMs sind in der Lage, Quellcode zu lesen, DAG-Strukturen zu verstehen und Transformationslogik zu interpretieren.
Daten-Orte — Wo liegen die Eingangsdaten? Wo landen die Ausgaben? Connection Strings, Bucket-Namen, Datenbankschemas — alles, was der Agent braucht, um Daten direkt zu inspizieren.
Helm Chart — Image-Tags, Environment-Variablen, Kubernetes-Ressourcen. Der Agent kann Helm Charts lesen und verstehen. Damit kennt er das Deployment-Setup.
Querverbindungen zwischen Artefakten — Code, Helm Chart, Kubernetes-Cluster und Daten-Orte müssen miteinander verbunden sein. Wenn der Agent in Node A einen Fehler vermutet, muss er von dort direkt zum Helm Chart und von dort zum laufenden Pod navigieren können, ohne dass ein Mensch den nächsten Schritt einleitet.
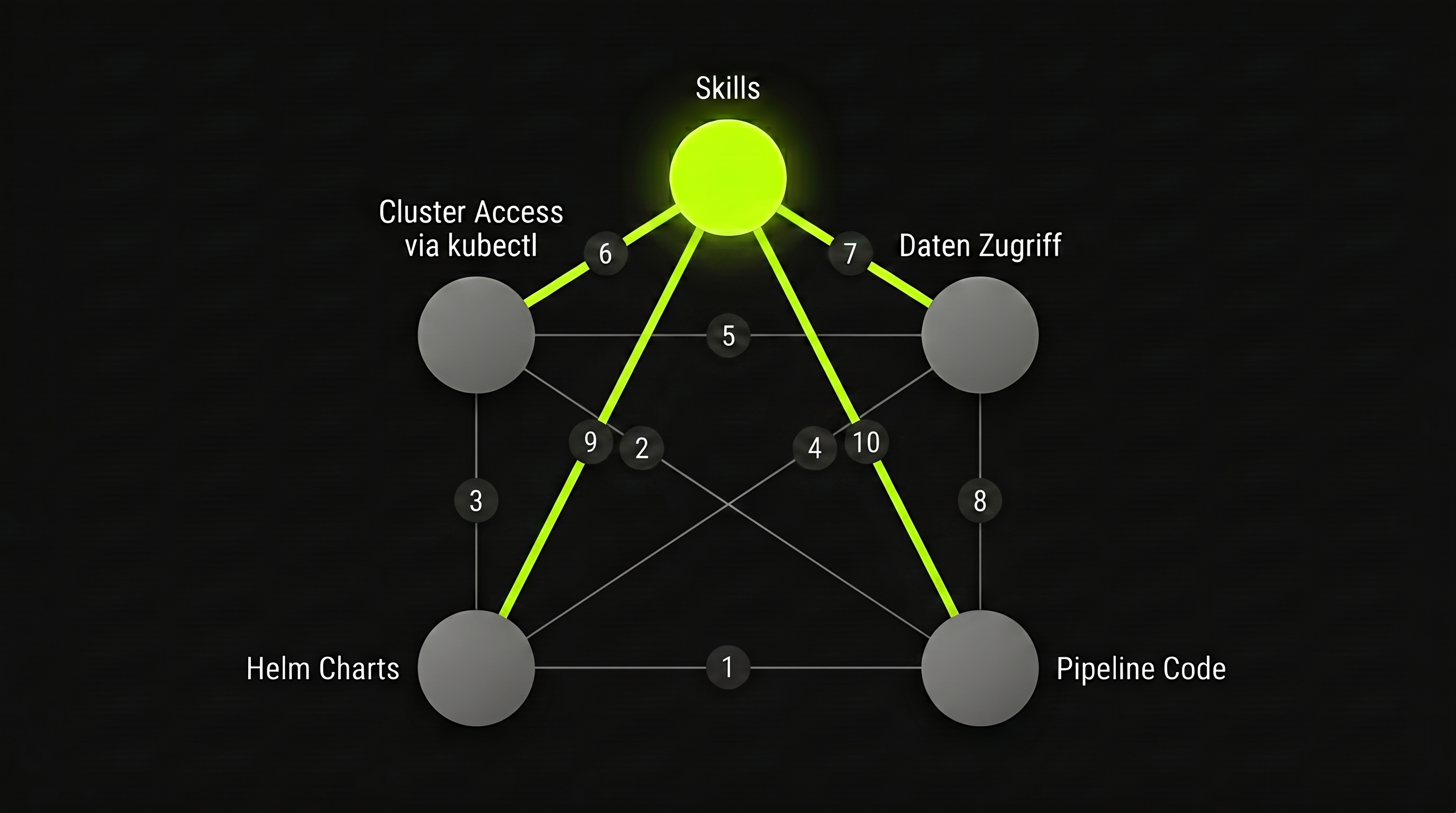
Diese vier Fundamente bilden im Bild oben aber nur das Quadrat am Boden des Hauses vom Nikolaus. Was sie zusammenhält, ist der fünfte Knoten an der Spitze — die einzige Node, an der alle vier lime Kanten zusammenlaufen:
Der Skills-Knoten ist der Bootstrapper. „Skills” sind die wiederverwendbaren Agent-Fähigkeiten — Rollen-Definitionen, Konventionen, Runbooks —, die dem Agenten sagen, wie er die vier Fundamente bedient. Ohne sie hat der Agent zwar Zugriff auf Code, Daten, Helm und Cluster, aber keinen Einstiegspunkt. Mit ihnen wird aus „kann lesen” ein „weiß, wo es losgeht”: Der Skills-Knoten bootstrappt den Betrieb — genau wie der User-Prompt die Generierung bootstrappt.
So sieht ein Skills-Knoten konkret aus
Damit das nicht abstrakt bleibt — hier ein anonymisiertes Beispiel einer realen Skill-Datei für ein Kundenprojekt, auf das Wesentliche reduziert. Sie verdrahtet genau die vier Fundamente und gibt dem Agenten Rolle, Konventionen und Runbook-Verweise an die Hand:
---
name: acme-pipeline-ops
description: >
Betreibt die Acme-Data-Pipeline: Monitoring, Debug, Extend und Ad-hoc-Runs.
Kennt Code, Daten-Orte, Helm-Chart und Cluster-Zugang.
---
# Pipeline-Betrieb – Kunde Acme
Du betreibst die Acme-Pipeline: Status-Fragen beantworten, Abweichungen
debuggen, den DAG erweitern und Runs triggern.
## Die vier Fundamente
| Fundament | Ort |
|-------------------|--------------------------------------------------|
| Pipeline-Code | .../dags/AcmeEtlMain (selbstbeschreibende Nodes) |
| Daten-Orte | Prod-PVC -> lokal spiegeln (Runbook sync-prod) |
| Helm Chart | .../charts/acme-pipeline (Image-Tags, ENV) |
| Querverbindungen | Code <-> Helm <-> Cluster <-> Daten |
## Cluster-/kubectl-Zugang
- Context `prod-cluster` -> 10.0.0.10:16443, Namespace `acme-prod`
- Status: kubectl -n acme-prod get cronjob / get pods
- Ad-hoc-Run: kubectl -n acme-prod create job --from=cronjob/etl-cronjob-acme run-manual
## Runbooks
- Debug "Zahlen stimmen nicht": DAG lesen -> Eingangsdaten inspizieren -> Code -> Fix + Re-Run
- Daten lokal spiegeln: Runbook sync-prod
- Infrastruktur-/Helm-Eskalation: an den DevOps-Skill delegieren
## Konventionen
- Code-Änderung immer als PR (Mensch reviewed)
- Jeder Fix mit Test; Image-Tag im Helm values.yaml pinnen
Kein Geheimwissen, keine Konfig-Magie — eine Markdown-Datei, die dem Agenten sagt, wo die vier Fundamente liegen und wie er sie bedient. Das ist der Bootstrapper.
Die laufende Pipeline ist der Bereich, wo Agentic AI am sichtbarsten Wert schafft. Vier Operationen, die heute meist manuell laufen, können vollständig agentengetrieben sein: Monitoring, Debug, Extend, Run.
Monitoring — Status ohne Log-Diving
> Hey Claude, hat der gestrige Run alle Nodes erfolgreich abgeschlossen?
→ Alle 5 Nodes erfolgreich.
847 Records verarbeitet, 12 neue CashFlows, 9 Belege gematcht.
CommerzBankSourceNode: 0 Fehler.
VerheirateNode: 3 Unmatched (wie gestern besprochen).
ReportNode: HTML-Output 2.1 MB, Versand-Mail an steuer@kunde.de versendet.
Der Agent liest den Audit-Trail des letzten Runs und beantwortet die Frage — ohne dass jemand Logs aufmacht oder ein Dashboard öffnet.
Debug — der Klassiker „Die Zahlen stimmen nicht”
Der Klassiker im Data-Engineering-Alltag. Kunde schreibt: „Die Auswertung von gestern zeigt eine Differenz von 4.230 €. Bitte schaut euch das nochmal an.” Kein Stack-Trace, kein Logging-Fehler, kein Alert — nur das Symptom.
So geht ein Agent mit dem richtigen Setup damit um:
Schritt 1 — DAG analysieren, relevanten Knoten identifizieren
Der Agent liest zunächst den DAG der Pipeline. In Reveal passiert das direkt aus dem Code — jede Node-Klasse ist selbstbeschreibend, und der Mermaid-Code der Pipeline gibt die Struktur wieder. Der Agent entscheidet anhand von Node-Typ (Transform, Match, Report) und Position im DAG, welcher Knoten für den gemeldeten Fehler in Frage kommt.
> Die Auswertung für gestern zeigt falsche Umsatzzahlen.
Welcher Teil der Pipeline ist betroffen?
→ Ich sehe im DAG drei mögliche Kandidaten:
· CashFlowNormalize
· VerheirateMatch
· ReportNode
Der Fehler liegt im finalen Report — ReportNode bekommt seine
Daten von VerheirateMatch. Ich schaue dort als nächstes.
Schritt 2 — Eingangsdaten inspizieren
Der Agent greift direkt auf die Eingangsdaten des verdächtigen Knotens zu. Er liest die tatsächlichen Rohdaten aus der Datenquelle — nicht Logs, sondern die Datensätze selbst.
→ Lese delta_input.parquet aus dem letzten Run-Folder.
47 Transaktionen vom gestrigen Tag.
12 davon haben CounterAccountId = "0" (als String).
Summe dieser Transaktionen: 4.230 €.
Das entspricht genau der Differenz im Report.
Schritt 3 — Fehlerursache im Code suchen
Jetzt geht der Agent zurück in den Code — konkret in die Klasse, die für den Matching-Schritt zuständig ist.
→ In VerheirateMatchNode.cs, Zeile 84:
.Where(t => t.CounterAccountId != null
&& t.CounterAccountId != "")
Problem: CounterAccountId = "0" rutscht durch.
Später schlägt der Join gegen die Konto-Tabelle fehl.
Vorschlag: int.TryParse + Prüfung auf > 0.
Schritt 4 — Fix einspielen und Pipeline neu starten
Der Agent passt den Code an, schreibt einen Test, baut über CI/CD ein neues Image, aktualisiert das Helm Chart und triggert einen manuellen Run.
→ Patch in VerheirateMatchNode.cs angewendet.
Test geschrieben: TestVerheirateMatch_FiltersZeroAccount → grün.
CI-Build: Image-Tag 2026-05-15-fix-counter-account erstellt.
→ Helm-Wert image.tag im values.yaml aktualisiert (Branch + PR).
→ Manueller Run gestartet:
kubectl create job --from=cronjob/verheirate-match \
verheirate-match-manual-20260515 -n reveal-prod
Run läuft. Ich melde sobald 12 Records gefiltert sind.
Extend — Pipeline erweitern
Neue Anforderung, neue Node, ohne den DAG neu zu zeichnen:
> Hey Claude, wir brauchen eine zusätzliche Validierung:
Buchungsbeträge über 10.000 € sollen ein Approval-Flag setzen,
bevor sie im Report landen.
→ Ich schalte eine neue Node zwischen VerheirateMatch und ReportNode:
BuchungsApprovalNode.cs
→ Logik: für jeden Eintrag Betrag > 10.000 €
Flag.RequiresApproval = true setzen.
ReportNode rendert solche Einträge in eigener Sektion.
→ DAG-DependsOn aktualisiert. Test geschrieben (3 Cases). Alle grün.
PR #142 erstellt — bitte reviewen.
Der Agent kennt die DAG-Topologie und kann Knoten an der richtigen Stelle einhängen.
Run — Ad-hoc-Runs ohne UI-Klick-Marathon
Drei Trigger-Wege, alle agent-zugänglich:
Scheduled CronJob — kubectl get cronjob liefert Frequenz, letzte und nächste Ausführung. Der Agent weiß, wann er das nächste Mal Daten erwarten kann.
Manueller On-Demand-Run — kubectl create job --from=cronjob/... triggert eine ad-hoc Ausführung. Der Agent startet sie und beobachtet die Logs.
Re-Run mit Override — values.yaml-Override für Datumsfilter, Tenant oder Dry-Run-Modus, alles per Prompt.
Das ist Operations ohne Operations-Person. Und falls ihr genau das nicht selbst aufsetzen und betreiben wollt: Unser Agent Ops Team übernimmt den agentengetriebenen Betrieb eurer Pipelines und Agents als Managed Service — Monitoring, Debug, Extend, Run inklusive.
Was Reveal hier ermöglicht

Beide Phasen — Generation und Operation — funktionieren heute, weil Reveal-Pipelines so gebaut sind, dass ein LLM direkt damit arbeiten kann:
- Selbstbeschreibende Node-Klassen — Jede Node enthält Metadaten über Input-Typ, Output-Typ und Transformationslogik. Ein Agent kann die gesamte Pipeline aus dem Codebase lesen, ohne Dokumentation.
- Mermaid-DAG im Code — Die Abhängigkeitsstruktur ist maschinenlesbar direkt im Repository — kein manuell gepflegtes Diagramm.
- Audit Trail — Jeder Pipeline-Run wird protokolliert. Der Agent kann Runs vergleichen und Regressionen erkennen.
- Kubernetes-nativ — Reveal läuft auf Kubernetes. Der Agent kann über
kubectldirekt eingreifen — Jobs triggern, Logs lesen, Image-Tags aktualisieren.
Für wen das relevant ist
Data Engineers und Berater, die Pipeline auf Pipeline implementieren: Das Setup-Investment (Repository-Struktur, Helm-Chart-Konventionen, Querverbindungen zwischen Artefakten) zahlt sich bereits ab der zweiten Pipeline aus. Generation wird ein halber Tag, Debug wird Minuten statt Stunden.
Software-Vendor-Teams, die Reporting- und Analytics-Features in ihr Produkt einbauen wollen: Wenn eure Kunden ihre Pipelines selbst erweitern und debuggen können — mit einem KI-Agenten als Interface — dann wird euer Produkt mit jedem Kundenwunsch besser, ohne dass ihr jede Anpassung selbst implementieren müsst.
BI-Teams, die ihr bestehendes BI nicht ablösen, aber erweitern wollen: Neue Datenquellen + neue Views per Prompt, kein IT-Ticket.
Der entscheidende Schritt ist nicht das LLM — das gibt es. Der entscheidende Schritt ist, die Pipeline-Infrastruktur so zu bauen, dass ein Agent überhaupt navigieren kann. Wer das einmal richtig aufsetzt, bekommt einen Mitarbeiter, der rund um die Uhr verfügbar ist, keinen Kontext verliert und sich über Routine-Debugging nicht beschwert.