yaico Plattform — Schicht 2
Reveal
Agentic First DAG Engine.
Die DAG-Engine die Claude versteht. Pipelines die ein KI-Agent auf Zuruf baut, debuggt und erweitert — mit Dashboards und „Talk with your Data" als Nodes im selben DAG.
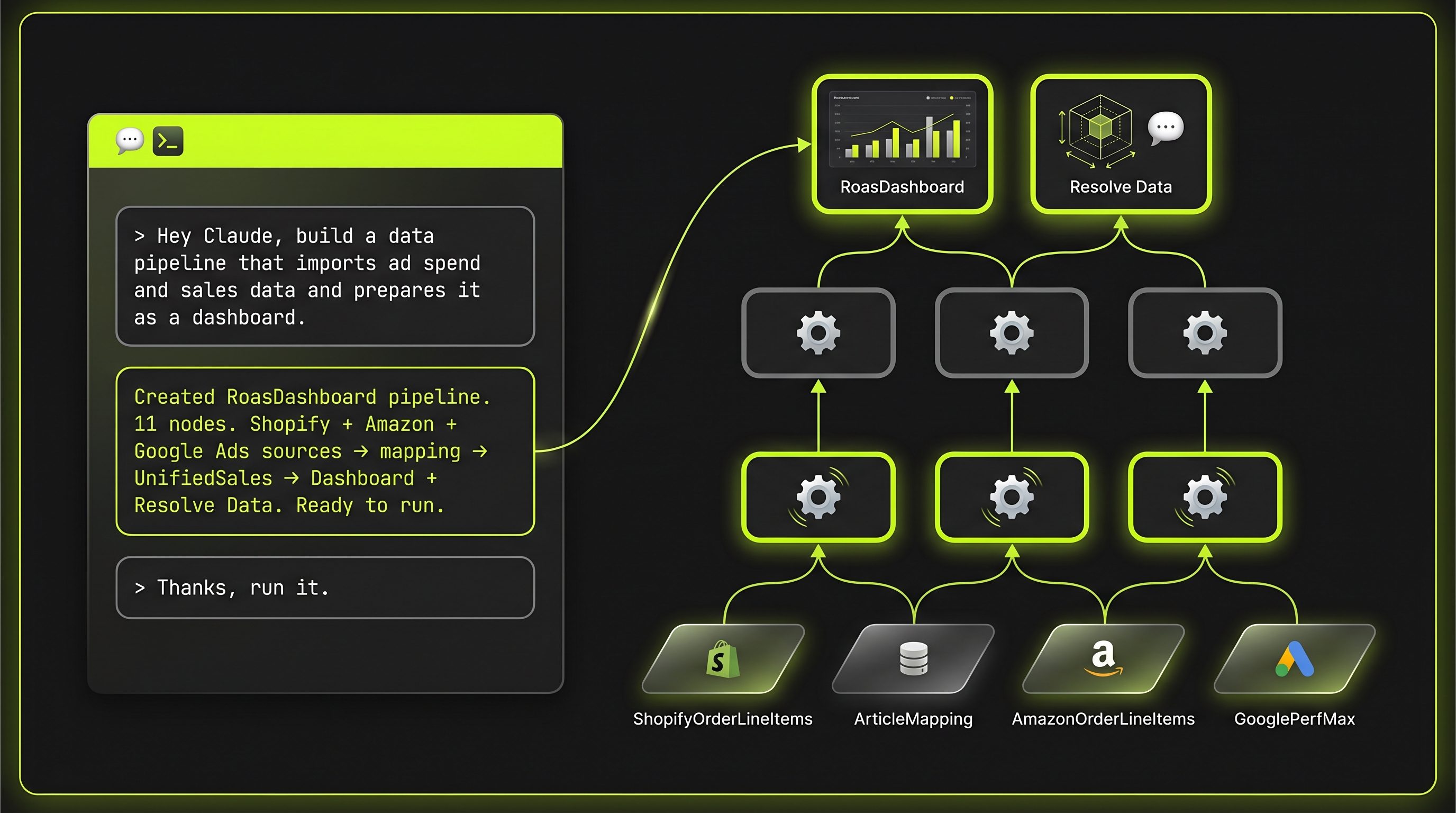
→ Das Ergebnis
Das Dashboard kommt direkt aus dem DAG.
Kein zweites BI-Tool, kein Export-Schritt. Der RoasDashboard-Node rendert das fertige HTML — als First-Class-Citizen im selben DAG.
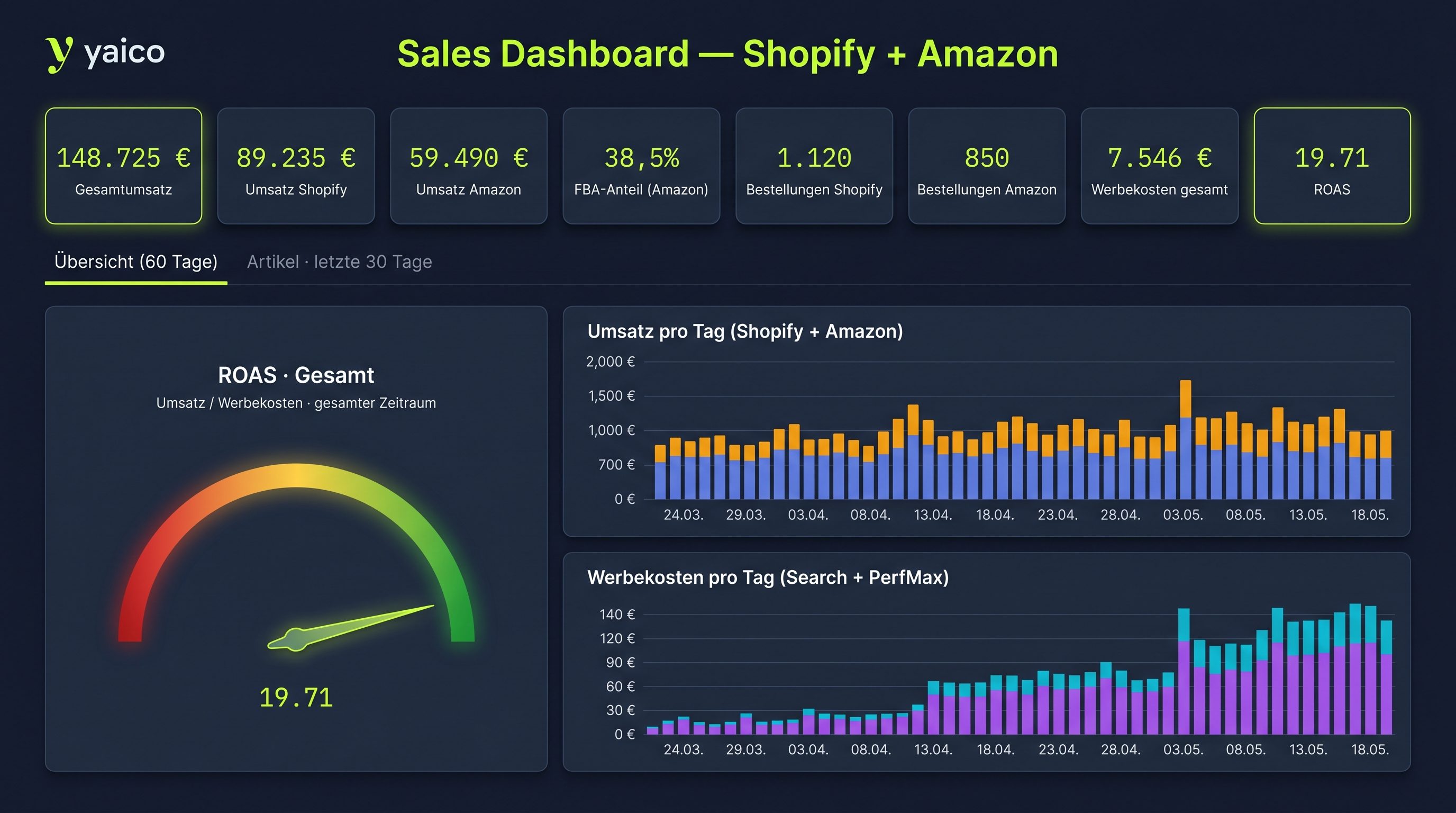
Aus Daten werden Zusammenhänge.
Reveal ist die DAG-basierte Transformations-Engine im Kern der yaico Plattform. Jeder Verarbeitungsschritt — vom Roh-Datenpunkt bis zum fertigen Kennzahlen-Datensatz — ist ein Node im Graphen: nachvollziehbar, reproduzierbar, auditierbar. Und: von einem KI-Agenten vollständig lesbar.
Agentic First.
Reveal-Nodes sind selbst-beschreibende Klassen. Keine Configs, keine versteckten Operatoren, keine Hidden Side Effects. Ein Claude-Kontext mit dem DAG-Code ist genug um die gesamte Pipeline zu verstehen — und zu erweitern.
Reveal ist für KI-Agenten optimiert: sie lesen, debuggen und erweitern Pipelines, der Mensch reviewed. Erstellung 5× schneller, weil Code und Configs nicht mehr von Hand gepflegt werden.
→ Konkret
In Action: eine neue Data Pipeline als DAG per Claude.
So sieht „Pipelines per Agent-Prompt" in echt aus — vom natürlichsprachlichen Auftrag bis zum lauffähigen Source-Code.
> Hey Claude, baue ein Sales-Dashboard, das Shopify- und Amazon-Bestellungen
zusammenführt.
→ Ich schaue mir die Reference-DAGs und die API-Docs in der Library an.
ShopifyOrderLineItemsNode und AmazonOrderLineItemsNode existieren bereits.
→ Lege SalesDashboardPipeline.cs an — zwei Source-Nodes, ein DashboardIndex,
Abhängigkeiten verdrahtet, Run-Aufruf am Ende:Das Ergebnis ist lauffähiger Source-Code, der sofort durch Claude getestet und optimiert wird, bis er das gewünschte Ergebnis produziert:
var ctx = PipelineContext.Create("/pipelineroot").EnsureDirectories();
var shopify = new ShopifyOrderLineItemsNode(ShopifyConnectorConfig.FromEnv(), context: ctx);
var amazon = new AmazonOrderLineItemsNode (AmazonSpApiConnectorConfig.FromEnv(), context: ctx);
var top = new DashboardIndexNode("Sales", ctx);
top.DependsOn(shopify);
top.DependsOn(amazon);
Helpers.RunSemDag(top, false, Console.WriteLine);2 Stunden statt 2 Tage — und das Ergebnis ist nicht ein Entwurf, sondern eine produktionsfähige Pipeline. Tests, Logging und Audit-Trail sind direkt mit dabei. Was bei dir landet, geht in den nächsten Cron-Run.
Zwei Dinge, die Reveal von anderen DAG-Engines unterscheiden.
Keine inkrementelle Verbesserung — zwei verteidigbare Architektur-Entscheidungen.
Der KI-Agent baut, debuggt und monitort die Pipeline. Reveal ist nicht „DAG-Engine mit AI-Add-on" — der Entwicklungs-Workflow setzt den Agenten voraus.
Dashboards, HTML-Reports und die OLAP-Artefakte für Resolve („Talk with your Data") werden als Nodes im selben DAG erzeugt — nicht in einem zweiten Tool danach.
Was Reveal mitbringt.
Sechs Bausteine — agentic-first, audit-sicher, produktionshärtet.
Agentic Interface
DAG-Code so strukturiert dass Claude (oder jeder andere LLM-Agent) den Graphen liest, Nodes versteht und eigenständig erweitert — ohne Framework-Einarbeitung. Debug, Extend und Monitor on demand.
Report Nodes
Fertige HTML-Reports und Dashboards werden während des ETL-Laufs erzeugt — als First-Class DAG-Nodes, nicht als separater Nachbearbeitungsschritt. Steuerberater bekommt den Report jeden Morgen automatisch.
DAG-Engine
Beliebig tiefe Abhängigkeitsgraphen. Jeder Node einzeln testbar und isoliert ausführbar. Source, Consolidation, Match, Transform, Output — alle in einem kohärenten Modell.
Audit-Trail
Jeder Lauf vollständig protokolliert — wann hat welcher Node welchen Output erzeugt. Buchungsvorschlag zurückverfolgen bis zum Quell-PDF. Prüfungssicher.
Automatische Propagation
Neue Quelldaten triggern nur die betroffenen Downstream-Nodes — kein Full-Reload. Effizient auch bei täglichen Runs mit großen Datenmengen.
Connector-Nodes
Google Ads, Meta, Shopify, Xentral, DATEV-Excel, Commerzbank, PayPal — native Source-Nodes direkt im DAG. Neuer Connector: eine abgeleitete Klasse, Claude schreibt den Boilerplate.
Für Berater, Vendors und BI-Teams.
Drei Rollen, drei Pain Points — alle gelöst mit Agentic First.
Berater & Data Engineers
„Ich implementiere Pipeline nach Pipeline für Kunden."
Der Pain: jede neue Datenquelle kostet 2–3 Tage Arbeit. Onboarding neuer Teammates dauert Wochen. Debugging bedeutet Log-Diving. Mit Reveal + Claude schreibt der Agent den Connector-Boilerplate, der Berater reviewt und deployt.
Software Vendors & ISVs
„Ich will meinem Produkt eine Data Pipeline Engine geben."
Der Pain: eine eigene DAG-Engine bauen und betreiben kostet ein Data-Engineering-Team. Mit Reveal als lizenzierbarer Komponente bekommt das Produkt eine fertige, produktionshärtete Engine — inklusive dem Agentic-Interface das eure Kunden nutzen können.
BI-Teams
„Ich will Agentic Analytics ohne unser BI zu ersetzen."
Der Pain: bestehendes BI ist statisch, neue Reports brauchen Wochen über IT-Tickets. Mit Reveal baut ihr neue Pipelines und Dashboards per Prompt auf euren BI-Daten auf — Resolve macht sie als „Chat with your Data" zugänglich. Kein Replatforming.
Reveal in der yaico Plattform.
Reveal ist Schicht 2 — zwischen Capture (Dokumente) und Resolve (Antworten).
Reveal läuft heute produktiv.
Nicht Konzept — sondern täglich ausgeführte Pipelines in ecommerce-GmbHs.
→ Tiefer eintauchen
Die Blog-Serie: KI-Agenten als Pipeline-Engineers.
Wie ein Agent eine Reveal-Pipeline generiert, deployt und betreibt — in drei Teilen.
Reveal live sehen — 20 Minuten reichen.
Wir zeigen euch wie ein Agent eure erste Pipeline debuggt und erweitert. Bringt gerne eine konkrete Datenquelle mit die ihr anschließen wollt.
→ 20 Minuten reden